
This year, the judges have selected a
shortlist of seven for the ALPSP Awards for Innovation in Publishing.
Each finalist will be invited to showcase their innovation to industry peers on
14 September on the opening day of the ALPSP 2022 Conference in Manchester.
In this series, we learn more about
each of the finalists. The winners will be announced at the Awards Dinner on
Thursday 15 September.

Tell us about your organization
There are about 20 of
us at Hum, and we are a fully remote organization. The idea of Hum developed
from Silverchair’s product innovation function. We were set up as a separate
company in late 2021 so that we could single-mindedly pursue an idea that we think
has the potential to transform publishing.
What is the project/product that you submitted for the Awards?
Hum is the product,
as well as the company name. One of the challenges we face in talking about Hum
is that there is a lot about it that is new and different. As a class of software,
Hum is a ‘Customer Data Platform’ (or CDP), but for most publishers that isn’t that
helpful a place to start since they aren’t that familiar with CDPs – although
they are going to get familiar with them because my view is that every
publisher (and society) will have a CDP as a central part of their tech stacks
and – more importantly –business practices, within 5 years.
So what do CDPs do? They integrate with the other systems and databases at an organization
and collect all of the relevant data about an audience (defined as everyone who
comes into digital contact with that organization, covering user, reader,
customer, reviewer, author, librarian, researcher, teacher, and learner, and so
on) and then they allow you to manipulate that data for business use. The
primary ways that organizations can use CDPs are via vastly improved segmentation and personalization. Sounds
simple, but it is the means for organizations to make data-driven decisions
about nearly everything they do.
At Hum, in addition to helping the publishing market to understand what CDPs
are, we need to highlight Hum’s critical differentiators from the class of
generic CDPs. These differentiators come from Hum’s focus as the only CDP built
for content-rich organizations (publishing, most obviously).
Tell us a little about how it works and the team behind it
Hum brings together
all of the first party data relating to a publisher’s audience and provides
that publisher with the tools to generate insights and take actions from that data.
The systems integrated with are likely to be publishing platforms, websites,
CRMs, commerce systems, marketing systems, and submission and peer review
systems, for example. The data is demographic (name, age, location, email,
title, university, library); transactional (a purchase made, a campaign email received); and behavioural
(reading all or part of a journal article, visiting a blog post, opening an
email, clicking on the email content, scrolling, carrying out a search, downloading
content, listening to a podcast, watching a video).
It is this final category (behavioural data) where Hum’s differentiation really
kicks in. You can generate significant insight and business benefit by
understanding how your audience is engaging with your content. Hum tracks at a
deep level every audience member’s interaction with content, capturing what is
being read, by whom, how deeply, when, etc. When this behavioural data about
interests and intent is tied together with other data (eg demographic and
transactional), a lot of exciting use cases become possible. But Hum does not just collect up all the data that a publisher is
already capturing (and in most cases not using). It generates significant new
data. Hum uses AI (and this is genuinely AI, based upon our own proprietary
development of Google’s BERT) to automatically tag every piece of content at a
publisher. Many publishers have their journal and book content tagged at some
level, but Hum automatically tags and assigns key words to ALL content (video,
podcast, blog, content marketing, social, marketing pages, etc). So Hum is
generating new data about a publisher’s audience’s engagement with a
publisher’s entire content set.
This focus on content is a big differentiator. But also very important is that
Hum is ‘built for humans’. While Hum is powerful it is also easy to use:
data-driven decision making becomes something that everyone in the publisher
can do, rather than requiring data scientists.
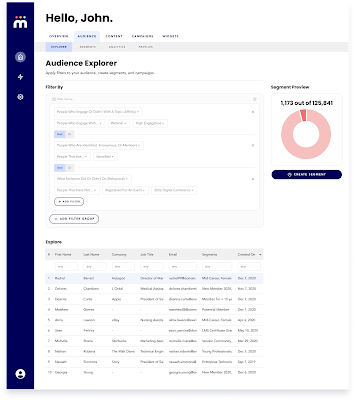
Hum is best understood by example. Say you want to market a new webinar. After implementing
Hum, you can use Hum’s ‘Audience Explorer’ to build in a matter of seconds a
precise segment that you think will be interested in that
webinar. That segment of interested people will automatically
be reflected in your email and advertising platforms to use for targeted messaging.
The segment is live, not static: when people sign up for the webinar, they are
removed.
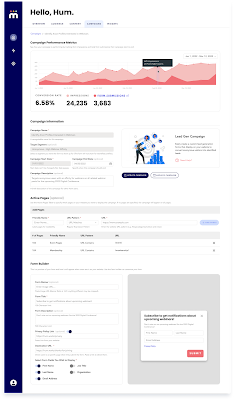
When new people qualify, they get targeted messages or ads. For your identified users (for whom you have an email), you can promote the webinar ‘off platform’, often via regular communications that are specifically tailored down to the individual and drive 150%+ lift in metrics like opens and click throughs. You can also target anonymous users on your own sites via popup modals, personalized ads and content recommendations (webinars are content too!). And if I had more time, I’d tell you about ‘Content Explorer’ that allows publishers to understand what content is (and is not) working, for whom, where, when, and so on, to help to devise content and product development strategies based not on guesswork but on actual audience interest and behaviour.
The biggest use cases in publishing are: improved marketing via segmentation
and personalization; improved ad targeting; author and reviewer acquisition;
content strategy; audience building and identification; B2B sales; and new
product development. As for the team, we are a mix of technologists, publishers, data scientists,
and sales, marketing, and delivery people. We joined Hum for its mission and
culture.
In what ways do you think it demonstrates innovation?
Hum is the first CDP
purpose-built for publishers. Publishers care a lot about their content. And so
do we. Our focus on content as a first-class artifact is a key Hum
differentiator amongst the broader CDP category, and it’s an area where much of
our innovation is demonstrated. We’re developing a few proprietary features
that help publishers evolve their content strategy and deepen their
understanding of how readers interact with content.
I’ll highlight a few
areas of content innovation:
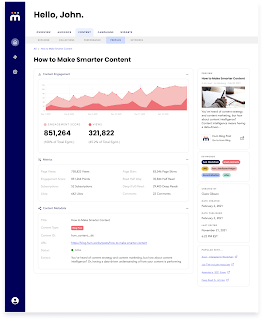
- Engagement Scoring:
What are your plans for the future?
Hum uses a proprietary engagement algorithm that gives publishers a sense for their best topics and subtopics by assigning values to various content metrics. It reads each piece for engagement metrics like full and partial reads, visits by segment, overall traffic, etc. It compares these article-level metrics to other pieces in the corpus to share comparative insights on content performance.
- cueBERT: A modified
version of Google’s BERT pre-trained model (trained on huge amounts of text),
tweaked to read content and understand what it’s about.
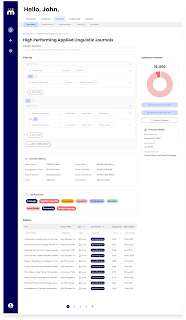
- cueBERT uses Natural Language Processing and machine learning to understand the entire body of content, normalize the tagging of that content, and iteratively improve Hum’s recommendations engine.
This feature pulls a lot of what I’ve just described together. It’s an interactive tool that allows you to drill down into your content and audience based on various search parameters. It lets publishers get a real-time look at important trends, answering questions like: What topics are resonating most with x group?; How big is x segment, and more importantly, how can we activate them?; Where are the gaps in our content strategy?; What are readers in x segment most engaged with?
About the author
Tim Barton, CEO

Relevant web links:
No comments:
Post a Comment